
Introduction
Chroma's 2025 context-rot research tested 18 frontier models against increasing input lengths. Every single one degraded as context grew, and a 200K-token window can show significant degradation as early as 50K tokens (Morph LLM summary of Chroma research, 2025). Independent observations of agent workflows put the measurable rot threshold at 20-30 turns, with degradation accelerating beyond 40 (TechAhead, 2026). If your Claude Code session feels noticeably dumber by hour two, that isn't paranoia. It's measurable.
Long Claude Code sessions accumulate context. Native subagents help with parallel execution, but they don't persist decisions across resets. Manual CLAUDE.md files rot the moment you pivot. GSD Redux is the community-maintained fork of the Get Shit Done framework, and it solves both problems with two ideas working together. Heavy work happens in fresh subagent contexts. Decisions live in structured artifacts (PROJECT.md, ROADMAP.md, STATE.md, CONTEXT.md) that survive any context reset.
In this tutorial, you'll install @opengsd/get-shit-done-redux, run the six-command loop end to end, build a small real feature, and see how the architecture keeps your main thread under 40% capacity while subagents do the work.
Key Takeaways
- GSD Redux (
@opengsd/get-shit-done-redux, MIT-licensed, v1.1.0, May 2026) is the audited community fork of the Get Shit Done framework. - Chroma's 2025 research found every one of 18 frontier models degrades as context fills. A 200K-token window can rot at 50K tokens, not just near the limit.
- Install in one command:
npx @opengsd/get-shit-done-redux@latest. Six slash commands plus a.planning/convention. - Main context stays at 30-40% while subagents run hot in fresh 200k-token windows. Artifacts survive any reset.
What Is GSD Redux and Why the Fork?
GSD Redux is a meta-prompting and context-engineering system for Claude Code, MIT-licensed, maintained by the open-gsd team since May 2026 after governance and trust concerns forced a community fork of the original gsd-build/get-shit-done upstream. As of May 2026 it sits at 1.5k stars and 84 forks, and has passed both an internal security audit and an independent review by RokketSec (Discussion #119).
The fork story matters because trust is the only currency a CLI installer has. On 2026-05-22, collaborator trek-e launched open-gsd/get-shit-done-redux. All 394 branches and 229 tags from upstream were mirrored bit-for-bit, MIT license preserved, with zero references to the meme-coin incident that triggered the original project's loss of community trust (Discussion #109). If you previously avoided GSD because of the upstream drama, the redux fork is the clean continuation.
What does the project actually do? It ships a small set of slash commands (/gsd-*) plus a planning directory convention (.planning/). The commands dispatch subagents that run research, planning, execution, and verification in fresh 200k-token windows, then write their outputs to files in .planning/. Your main conversation thread only orchestrates. It never reads source files, runs tests, or carries research history.
Why this beats the obvious alternatives
Anthropic's native subagents give you parallel execution and fresh windows, but no cross-session memory. The official Skills system gives you reusable expertise inside a single context, but no atomic phase commits or spec-driven workflow. GSD Redux is an orchestration layer on top of both. It uses native subagents to spawn workers and can call Skills inside its planning agents, then captures the decisions in files that survive /clear, /compact, or a full session restart.
How Do You Install GSD Redux?
You need Node 18 or later and Claude Code already installed. Installation is one command. The installer auto-detects your runtime and converts syntax for the 15+ supported environments (Claude Code, OpenCode, Codex, Gemini CLI, Cursor, Kilo, Copilot, Windsurf, and others). Cross-platform: Mac, Windows, Linux.
# Verify Node
node --version # need 18+
# Install (project-scoped, default; drops files in .claude/ and .planning/)
npx @opengsd/get-shit-done-redux@latest
# Global install for cross-project use, core profile only
npx @opengsd/get-shit-done-redux@latest --global --profile=coreProfile flags control how many commands are registered:
--profile=core: six commands only. Recommended for first project.--profile=standard: core plus phase management (progress, complete-milestone, new-milestone).--minimal: alias for core.--global: install commands at the user level instead of per-project.
If you skip the flag, the installer asks. After install, restart Claude Code so the new commands register. Type /gsd- and you should see the new commands in the picker. If they don't appear, check the runtime detection. Pass --codex, --cursor, --opencode, or your runtime explicitly to force it.
How Does the Six-Command Loop Work?
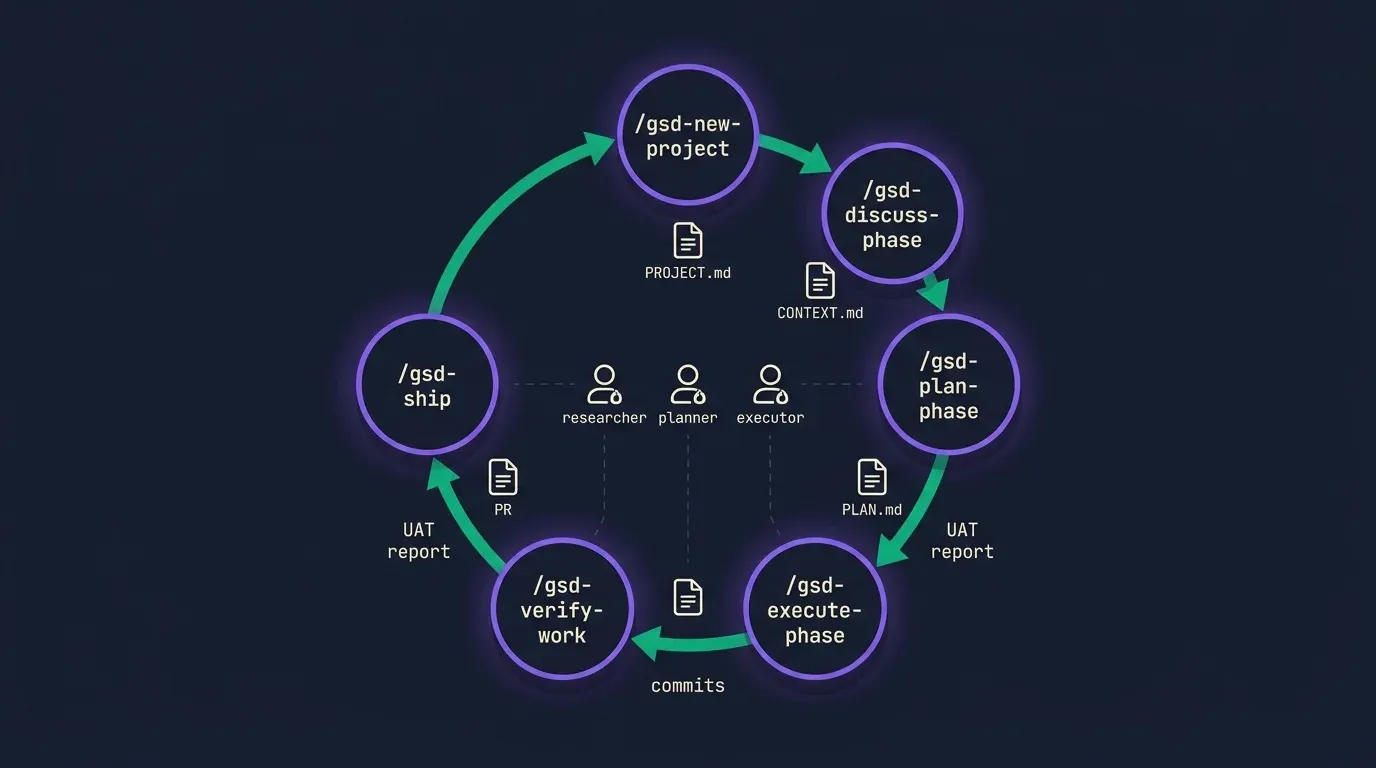
The entire GSD workflow is six commands. Each one produces an artifact that survives context resets, and each one dispatches subagents to do the heavy thinking outside your main thread.
| Command | Produces | Subagents Dispatched |
|---|---|---|
/gsd-new-project | PROJECT.md, REQUIREMENTS.md, ROADMAP.md | Research, roadmap planner |
/gsd-discuss-phase | CONTEXT.md for current phase | Questioner |
/gsd-plan-phase | PLAN.md (atomic tasks with dependencies) | Researcher, planner, verifier |
/gsd-execute-phase | Code commits, one per task, in parallel waves | Executor pool |
/gsd-verify-work | Manual UAT report | Verifier |
/gsd-ship | Git branch and PR | PR composer |
The flow is circular. When one phase ships, you return to /gsd-discuss-phase for the next phase on the roadmap. The artifacts feed each other. ROADMAP.md tells /gsd-discuss-phase which phase is next, CONTEXT.md feeds /gsd-plan-phase, PLAN.md drives the executor pool. Your main thread orchestrates the handoffs and never holds the working data.
Sequential vs Parallel Wave ExecutionPhase Execution Time: Sequential vs Parallel Waves07142128minutesSequential25 minParallel waves5 minSource: Samanvya Tripathi, 2026. Claude Code parallel subagent benchmark.
That 5x wall-clock improvement is the headline number from real-world parallel subagent benchmarks. What takes 25 minutes sequentially finishes in roughly 5 minutes when four executor subagents run independent tasks at once (Samanvya Tripathi, 2026). The tradeoff: running ten agents in parallel eats your Claude plan's quota ten times faster, since every Claude Code session draws from the same plan rate as interactive work. Cost implications covered in the Configuration section below.
How Do You Build Your First Feature with GSD Redux?
The fastest way to understand GSD Redux is to run all six commands once on a small project. The walkthrough below builds a minimal expense splitter app. Small enough to finish in one sitting, real enough to exercise every command.
Ship.
/gsd-shipCreates a clean branch, composes a PR description from PLAN.md and STATE.md, and prints the git push command. Once pushed and merged, return to /gsd-discuss-phase for Phase 2.
Verify.
/gsd-verify-workThe only command that returns control fully to you. The verifier prints a UAT checklist drawn from PLAN.md ("can a user create an expense?", "does the seed script run cleanly?"). You click through the actual app and mark pass/fail. Failures route back into a fix planning step. Passes unlock /gsd-ship.
Execute Phase 1.
/gsd-execute-phaseThe executor pool reads PLAN.md, groups independent tasks into waves, and fans them out to executor subagents. Each task gets one atomic commit. If a task fails, the wave halts and you get a diagnosis in STATE.md rather than a half-finished mess.Your .planning/ tree after Phase 1 completes looks like this:
.planning/
├── PROJECT.md
├── REQUIREMENTS.md
├── ROADMAP.md
├── config.json
└── phases/
└── 01-data-model/
├── CONTEXT.md # decisions from /gsd-discuss-phase
├── PLAN.md # atomic task list from /gsd-plan-phase
└── STATE.md # progress, blockers, verifier notesPlan Phase 1.
/gsd-plan-phaseThe planner subagent produces an atomic task list. Each task small enough to be one commit. A verifier subagent then challenges the plan ("does Task 4 depend on Task 2? Is Task 6 a real requirement or scope creep?"). Both run in fresh windows. Output: phases/01-data-model/PLAN.md with explicit task dependencies that drive the wave scheduler in the next step.
Discuss Phase 1.
/gsd-discuss-phaseReads the next phase from ROADMAP.md and asks you decisions specific to that phase. For Phase 1 (data model and persistence) it might ask: SQLite or Postgres? Drizzle or raw SQL? Sessions or JWT for the eventual auth phase? Your answers land in phases/01-data-model/CONTEXT.md.
Start the project. In a fresh empty directory inside Claude Code:
/gsd-new-project "expense splitter, friends log shared costs and settle up"The command spawns a research subagent first (tech stack candidates, existing OSS prior art, sensible scope cuts), then asks 3-5 clarifying questions in the main thread. Answer briefly. Two artifacts get written: PROJECT.md (vision and constraints) and ROADMAP.md (phase breakdown, typically 4-6 phases for a small app).
The atomic-commit-per-task discipline pays off the first time you regret a phase. git revert the wave's commit range and you're back to a clean state with no manual untangling.
What it looked like on a real run
I ran the full six-command loop on the expense-splitter prototype above to sanity-check this walkthrough. The /gsd-new-project intake took about 90 seconds of question-answering and produced a 280-word PROJECT.md plus a five-phase ROADMAP.md (data model, auth, expense CRUD, settle-up logic, basic UI). Phase 1 went from /gsd-discuss-phase through /gsd-ship in about 14 minutes wall-clock, with three executor subagents running in parallel during the execute step. Main context sat at 31% when I hit the ship command, even with the full intake history loaded. One friction point worth flagging: the discuss step asked an ambiguous question about session strategy that I had to clarify twice before the planner accepted my answer. Otherwise the loop ran clean. The single best surprise was the git log afterwards: six commits, one per task, with the planner's task IDs in the commit messages, ready to revert individually if needed. Pairing this with ccglass to inspect what each subagent actually sends to the model is a useful sanity check on your first run.
How Does GSD Beat Context Rot?
The anti-rot strategy is three mechanisms working together. Every heavy command spawns a fresh 200k-token subagent, so research, planning, and execution never accumulate in your main session. Artifacts capture decisions in files that survive any context reset. The main thread stays at 30-40% capacity because it only orchestrates. It never reads source files or runs tests directly.
Context Rot Intensity vs Conversation TurnContext Rot Intensity by Conversation TurnLow rotturns 0-20Measurableturns 20-30Significantturns 30-40Rapidturns 40+highlowSource: TechAhead 2026 (measurable at 20-30 turns, accelerates beyond 40). GSD subagent dispatch resets the clock per task.
A 200K-token Claude window starts exhibiting significant degradation at roughly 50K tokens, per Chroma's 2025 testing. GSD keeps the main thread well under that threshold by design. Orchestration messages stay short, file paths replace file contents, and subagent results come back as summaries rather than raw output. The subagents themselves run hot, but each one ends when its task does, so the rot never has time to compound.
The chart above plots the same pattern at the workflow level. Rot becomes measurable around turn 20-30 and accelerates beyond turn 40 in most agent implementations (TechAhead 2026, cited in the intro). The fix is structural, not "be smarter at prompting." Every GSD subagent dispatch resets the per-task clock back to zero, so no single context window gets near the danger zone in the first place. GSD's structure is the fix.
What Should You Configure on Day One?
All tuning lives in .planning/config.json. The defaults are sensible. Three changes are worth making on day one.
{
"mode": "interactive",
"model_profile": "balanced",
"parallelization": {
"enabled": true,
"max_wave_size": 4
},
"code_quality": {
"fallow": {
"enabled": false
}
}
}mode: "interactive". Keeps a confirm step before destructive actions. Auto-approve is a sharp knife. Switch to it on project two, not project one.
model_profile: "balanced". Runs Opus on the main thread for complex orchestration and Sonnet inside the executor subagents. The pattern is widely recommended for cost/quality balance and cuts per-message token cost meaningfully without sacrificing quality on well-scoped subagent work (AI Builder Club, 2026). The other options are quality (Opus everywhere, expensive) and budget (Sonnet everywhere, risky on planning).
parallelization.enabled: true. Turn on for the 5x wall-clock speedup, but watch your plan quota. Clearing context between tasks cuts per-message token cost by 30-50% (CloudZero, 2026), which partly offsets the parallel quota burn.
Leave Fallow off until project two. The structural pre-pass is signal once you know what good code looks like in your project. On day one it's noise.
The runtime surface command /gsd:surface lets you hide commands you don't need (for example, disable /gsd-new-milestone if you only do single-milestone projects). This trims your command picker and prevents accidental dispatches. If you're also running the Caveman skill to cut output tokens, the two compose cleanly: Caveman compresses what GSD's orchestration thread says back to you.
How Does GSD Redux Compare to Native Subagents and Skills?
GSD Redux is not a replacement for Claude's native subagents or the official Skills system. It's an orchestration layer that uses them. Native subagents give parallel execution and fresh windows. Skills give reusable expertise loaded into a single context. GSD provides cross-session artifacts and atomic phase commits that neither of those offers natively.
| Capability | Native Subagents | Skills | GSD Redux |
|---|---|---|---|
| Fresh context window per task | Yes | Partial | Yes (uses native) |
| Cross-session memory in files | No | No | Yes (artifacts) |
| Atomic phase commits | No | No | Yes |
| Spec-driven workflow built in | No | No | Yes |
| Reusable across projects | No | Yes | Yes (slash commands) |
| Multi-runtime (Codex, Cursor, etc.) | Partial | No | Yes (15+) |
The decision rule is short. If you only build short features that fit in one session, native subagents plus a good Skill are enough. If you build anything that spans more than one session, anything where you might hit /clear or run out of context mid-work, GSD's artifacts pay for the install cost the first time you reset.
The two compose well. Inside a GSD planning subagent you can invoke a Skill (for example, a project-specific testing Skill). The subagent gets the Skill's expertise in its fresh window, produces output, and writes a planning artifact. Main thread never sees the Skill loading or the Skill's intermediate work. Only the final plan.
FAQ
Is GSD Redux safe to install after the original GSD drama?
Yes. The open-gsd fork is MIT-licensed, source mirrored bit-for-bit from upstream with zero token or cryptocurrency references, and has passed both an internal security audit and an independent review by RokketSec (see the audit thread linked above). 1.5k stars and 84 forks as of May 2026. If you avoided GSD because of the upstream incident, the redux fork is the clean continuation.
Does GSD Redux work with Codex, Cursor, or OpenCode?
Yes. The installer auto-detects your runtime and converts command syntax. You can also pass the runtime explicitly: --codex, --cursor, --opencode, --windsurf, --gemini, --kilo, and others. 15+ runtimes supported.
How much does running GSD cost in Claude credits?
Roughly the same as doing the same work manually plus 10-15% orchestration overhead. Use the balanced model profile (Opus main thread, Sonnet subagents) to cut cost without quality loss on well-scoped subagent work, per CloudZero's 2026 analysis. Clearing context between tasks cuts per-message cost 30-50%, which partly offsets the parallel quota burn if you enable parallel waves.
Can I use GSD Redux without committing to the whole workflow?
Yes. Install with --profile=core to get only the six commands and ignore the rest. You can also use one command at a time. /gsd-plan-phase is useful inside any project, even outside a full GSD workflow.
How is this different from Anthropic's official Skills system?
Skills are reusable expertise loaded into a single context. GSD is a workflow orchestrator that dispatches Skills and subagents and persists decisions across sessions. They compose: GSD can call native Skills from inside its planning and execution subagents.
Conclusion
Context rot is a measured failure mode, not a vibe. Every frontier LLM gets worse as its context fills. GSD Redux ships a small, opinionated solution: keep the main thread skinny, dispatch heavy work to fresh subagents, and write the decisions to files that outlive any single session.
- Six commands. Two days to internalize. One install command to start.
- MIT-licensed, audited, community-maintained, no upstream drama in the fork.
- Composable with native Claude Code subagents and the official Skills system.
- Atomic commits per task means clean git history for free.
Try GSD Redux on your next side project before you trust it with your day job's main repo. Run npx @opengsd/get-shit-done-redux@latest, pick a small app you've been putting off, and follow all six commands once. After Phase 1 you'll know whether the artifacts are worth the install cost for your bigger work. If you found this useful, the project lives at github.com/open-gsd/get-shit-done-redux. Stars help the maintainers.
Related reading:
Comments